2021-01-23
Hibernate配置文件
1 |
|
1 |
|
1 | Configuration configuration = new Configuration().configure(核心配置文件名称);//加载指定名称的配置文件 |
SessionFactory它不是轻量级的,所以不要频繁创建关闭它。在一个项目中有一个SessionFactory就可以了,通过SessionFactory来获取Session进行操作。那么问题来了,怎样可以保证在一个项目中所使用的SessionFactory是同一个呢?我们得抽取一个工具类,可在com.meimeixia.hibernate.utils包下创建一个工具类(HibernateUtils.java)
1 | package com.meimeixia.hibernate.utils; |
获得session的两个方法
SessionFactory.openSession():相当于直接通过SessionFactory创建一个新的Session,使用完成后要手动调用close()方法来关闭;
SessionFactory.getCurrentSession():获取一个与线程绑定的Session,当我们提交事务或事务回滚后会自动关闭。

save:保存方法
它主要用作保存对象
get/load:查询方法
get方法和load方法都是根据id来查询对象,虽然用起来就那么回事,但是它们之间是有本质区别的。而且Hibernate中的get方法和load方法的区别是常考的面试题,所以,于情于理我们都应该彻底地弄懂它们。
update:修改方法
修改操作一般都会有两种方式:
- 第一种方式:直接创建对象再进行修改(不推荐)

第二种方式:先查询,再修改,推荐使用这种方式。

delete:删除方法
删除操作一般也会有两种方式:

saveOrUpdate:保存或更新
我是感觉这个方法很傻逼!智障的不是一点,说到底其实就是数据库表中如果没有一条相对应的记录,这个时候你调用该方法,执行的就是保存操作。但如果数据库表中已经有了一条相对应的记录,那么这个时候你调用该方法,执行的就是更新操作。
查询所有

查询所有,还有一种方式,那就是使用本地SQL语句查询。这种方式适用于所要编写的SQL语句特别复杂,这时就有可能会用到。

Transaction:事务对象
Transaction接口主要用于管理事务,它是Hibernate的事务接口,对底层的事务进行了封装。使用它可以进行事务操作。例如:
事务提交:commit()
事务回滚:rollback()
获取一个Transaction对象呢?我们可通过如下代码获得:
Transaction transaction = session.beginTransaction();
1
第二个问题又来了,如果在程序中没有开启事务,是否存在事务呢?存在事务,默认session的每一个操作就会开启一个事务,并且默认情况下事务是不会自动提交的,相当于在Hibernate的核心配置文件中有如下配置:1
2
3
4
5
6<!-- 用于设置事务提交方式,默认是不自动提交的 -->
<property name="hibernate.connection.autocommit">false</property>
如果我们将其修改为:
<property name="hibernate.connection.autocommit">true</property>
则此时事务就会自动提交。
持久化类的编写规则
对于Hibernate中的持久化类,有如下编写规则:
必须提供一个无参数的public构造方法,这是因为Hibernate底层需要通过反射来生成实例;
所有属性要用private修饰,对外提供public的get/set方法,这是因为Hibernate需要获取或设置属性的值;
在持久化类中必须提供一个标识属性,让它与数据库中的主键相对应,我们管这个属性叫OID。
Java中是通过对象的地址来区分是否是同一个对象的,而在数据库中是通过主键来确定是否是同一个记录的,最后在Hiberimate中是通过持久化类的OID属性来区分是否是同一个对象的。Hibernate使用OID来建立内存中的对象和数据库中记录的对应关系。对象的OID和数据库的表的主键对应。为保证OID的唯一性,应该让Hibernate来为OID赋值。
持久化类中的属性尽量使用基本数据类型的包装类来定义,这是因为基本数据类型的包装类的默认值是null,而基本数据类型的默认值是0,搞不好这个0就会有很多的歧义;
持久化类不能使用final修饰符修饰,这是因为与延迟加载有关系,延迟加载本身是Hibernate一个优化的手段,它返回的是一个利用javassist技术产生的代理对象。javassist技术可以对没有实现接口的类产生代理,该技术其实使用了非常底层的字节码增强技术,继承这个类进行代理,即可产生一个代理对象,如果一旦这个类不能被继承,那么它就不能产生代理对象,这样一来,延迟加载就失效了,Hibernate就不能进行优化了,load方法就和get方法一点区别也没有了。
Hibernate的主键生成策略
主键的分类
定义hbm.xml映射文件和POJO类时都需要定义主键,Hibernate中定义的主键类型包括自然主键和代理主键:
- 自然主键(也称之为业务主键):主键的本身就是表中的一个字段(实体中的一个具体属性),也即具有业务含义的字段作为主键。比如说创建一个人员表,人员都会有一个身份证号(唯一的不可重复的),如果使用了身份证号作为主键,那么这种主键就称为是自然主键;
- 代理主键(也称之为逻辑主键):主键的本身不是我们表中必须的一个字段(不是实体中的某个具体属性),也即不具有业务含义的字段作为主键。比如说还是创建一个人员表,没有使用人员中的身份证号,用了一个与这个表根本不相关的一个字段,例如ID、PNO,那么这种主键就称为是代理主键。
建议:在企业开发中,尽量使用代理主键!因为一旦你的自然主键参与到了你的业务逻辑当中,那么后期就有可能要修改源代码。一个好的程序的设计,要满足一个OCP原则,即对程序的扩展是open的,对修改源码是close的。
主键生成策略
在实际开发中,一般不允许用户手动设置主键,一般会将主键交给数据库或者手动编写程序进行设置。在Hibernate中为了减少程序编写,提供了很多种主键的生成策略。
演示native主键生成策略


由于是mysql数据库,自动选择identity,并且使用mysql的自动增长机制
increment主键生成策略
你要是采用increment这种主键生成策略,应该在单线程程序中使用,一定不要在有多线程的情况下使用。
identity主键生成策略


演示uuid主键生成策略
主键是使用Hibernate中的随机方式生成一个的字符串。
将实体类(例如Customer.java)中的cust_id属性的类型由Long改为String,因为uuid这种主键生成策略适用于字符串类型的主键。

assigned主键生成策略



持久化类的三种状态

瞬时态
瞬时态也叫做临时态或自由态,它一般指我们new出来的对象,它不存在OID,且与Hibernate Session无关联,在数据库中也无记录。它使用完成后,会被JVM直接回收掉,它只是用于信息携带。如果要是一个对象没有唯一的标识OID,而且没有被Session所管理(咋叫被Session所管理啊?指的就是你得调用Session的方法,把这个对象交给Session,这个时候才叫作被Session所管理),那么这种对象就称被之为是瞬时态对象。
持久态
在Hibernate Session管理范围内,它具有持久化标识OID。它的特点是在事务未提交前一直是持久态,当它发生改变时,Hibernate是可以检测到的。简单来说,如果要是一个对象有唯一标识OID,且被Session所管理,那么这个对象就被称之为是持久态对象。
脱管态
脱管态也叫做游离态或离线态,它是指持久态对象失去了与Session的关联,脱管态对象它存在OID,在数据库中有可能存在,也有可能不存在。对于脱管态对象,它发生改变时Hibernet不能检测到。简单来说,如果要是一个对象有唯一标识OID,但没有被Session所管理,那么这个对象就被称之为是脱管态对象。

托管态==》瞬时态
托管态要想转换为瞬时态,可以直接将cust_id删除,即customer.setCust_id(null);。不建议这么做,因为我们不建议操作脱管态的对象。

持久态对象的特性
重点要研究的是持久化类的持久状态的对象,因为这个对象有一个非常特殊的能力,即持久化类的持久状态的对象可以自动更新数据库。

Hibernate一级缓存的概述
Hibernate框架中提供了很多种优化手段,其中包括缓存和抓取策略。仅从缓存来说,Hibernate提供了二种缓存机制,分别为:
- 一级缓存:Hibernate的一级缓存又被称为是Session级别的缓存,一级缓存的生命周期与Session一致,也就是说Session创建了,一级缓存也就存在了,因为一级缓存是由Session中一系列的Java集合构成的,而且一级缓存是自带的、不可卸载的;
- 二级缓存:Hibernate的二级缓存是SessionFactory级别的缓存,它是需要配置的缓存,也就是说二级缓存默认是不开启的,你要想使用二级缓存,你得自己去进行配置。二级缓存在企业开发中基本上已经不用了,因为我们一般都会用Redis,Redis就可以替代Hibernate的二级缓存。
Hibernate中一级缓存的内部结构
Hibernate的一级缓存就是指Session缓存。通过查看Session接口的实现类——SessionImpl.java的源码可发现有如下两个类:

在Session中定义了一系列的集合来存储数据,它们构成了Session的缓存。只要Session没有关闭,它就会一直存在。当我们通过Hibernate中的Session提供的一些API,例如save()、get()、update()等方法进行操作时,就会将持久化对象保存到Session中,当下一次再去查询缓存中具有的对象(通过OID值来判断),就不会去从数据库中查询了,而是直接从缓存中获取。Hibernate的一级缓存存在的目的就是为了减少对数据库的访问。
一级缓存中特殊的区域——快照区
前面,我举例演示过持久态对象具有自动更新数据库的能力,其实这种能力是基于Hibernate一级缓存的基础之上的。
首先,我们在HibernateDemo03单元测试类中编写如下方法:

运行以上demo02()方法,将发现数据库cst_customer表中,id为1的那条记录的cust_name字段变为”张小敬”,这再一次说明了持久态对象具有自动更新数据库的能力。但是,为什么持久态对象具有自动更新数据库的能力呢?原因涉及到一级缓存中一个特殊的区域——快照区,快照就是当前一级缓存里面对象的散装数据(对象的属性,如name、id……)。当执行完以下这句代码:
1 | Customer customer = session.get(Customer.class, 1l); |
就会向一级缓存中存储数据,一级缓存其底层使用了一个Map集合来存储,Map的key存储的是一级缓存对象,而value存储的是快照。通过在这句代码上打个断点,然后以debug的方式运行,Watch一下session会看得更加清楚,如下:

当事务提交,session关闭,向数据库发送请求时,那么就会判断一级缓存中的数据是否与快照区一致,如果不一样,就会发送update语句,也即自动更新数据库。

一级缓存常用API
一级缓存具有如下特点:
- 当我们通过Session的save、update、saveOrUpdate方法进行操作时,如果一级缓存中没有对象,那么会从数据库中查询到这些对象,并存储到一级缓存中;
- 当我们通过Session的load、get、Query的list等方法进行操作时,会先判断一级缓存中是否存在数据,如果没有才会从数据库中获取,并且将查询的数据存储到一级缓存当中;
- 当调用Session的clse方法时,Session缓存将被清空。


事务的四个特性

不考虑事务的隔离性,会产生什么问题?
如果不考虑事务的隔离性,那么就会产生如下问题:
- 脏读:一个事务读取到了另一个事务的未提交数据;
- 不可重复读:一个事务读取到了另一个事务提交的数据(主要是指update操作),会导致两次读取的结果不一致;
- 虚读(也叫幻读):一个事务读取到了另一个事务提交的数据(主要是指insert操作),会导致两次(也有可能是多次)读取结果不一致。
Hibernate中设置事务隔离级别
事务回顾完之后,我们已经知道了通过设置事务的隔离级别来解决不考虑事务的隔离性会产生的问题,那么你不仅要问,在Hibernate中如何设置事务的隔离级别呢?Hibernate框架中可通过hibernate.connection.isolation属性来设置事务的隔离级别,它可取的值有1、2、4、8。

在Hibernate框架中设置事务的隔离级别,可在hibernate.cfg.xml核心配置文件中添加如下配置:
Hibernate解决Service层的事务管理
要想进行事务管理的话,我们都知道事务都是加在Service层的,也就是说事务通常也被称之为是Service层的事务
Hibernate提供了三种管理Session的方式,在Hibermate的核心配置文件中,hibernate.current_session_context_class属性就是用于指定Session的管理方式的,该属性的可选值包括
- thread:Session对象的生命周期与本地线程绑定。本地线程绑定Session这种方式的大概内部原理可用下图来表示:
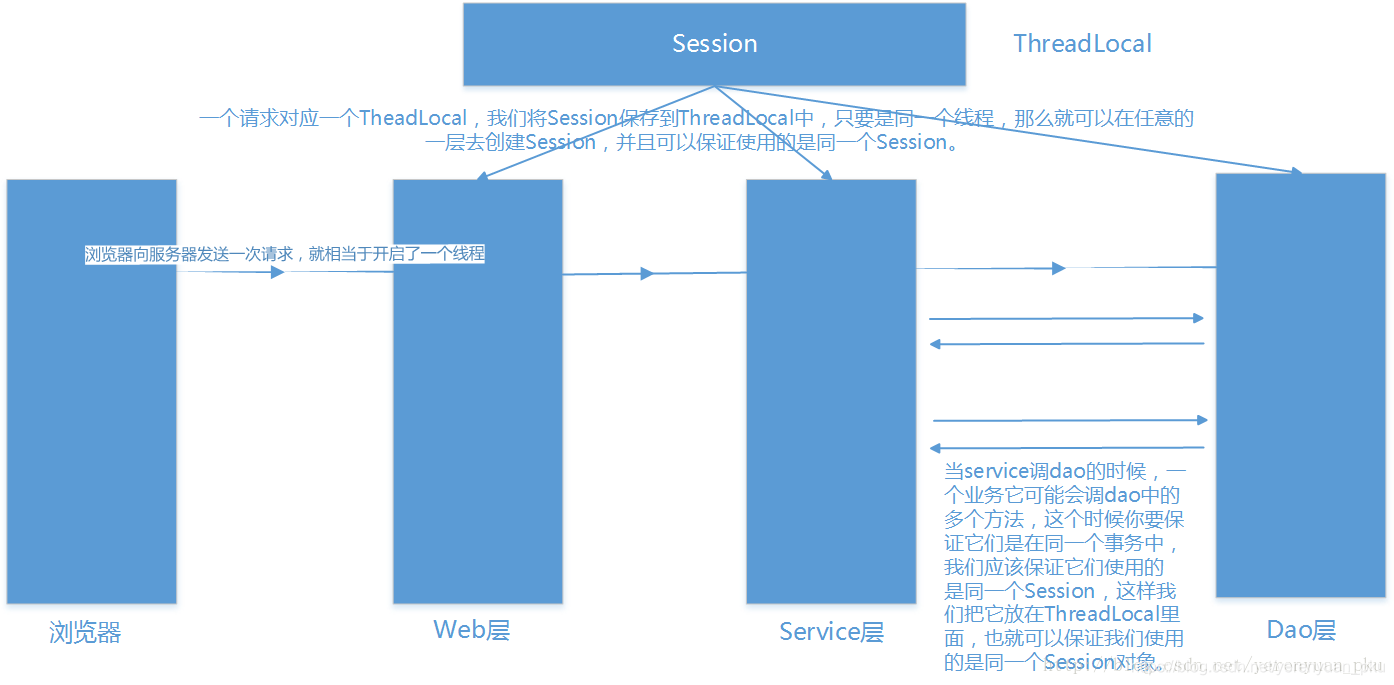
- jta:Session对象的生命周期与JTA事务(即跨数据库的事务,啥叫跨数据库的事务呢?我打个比方,比如说我往MySQL中执行了一个操作,又往Oracle里面也执行了一个操作,这个时候,我要保证它俩在一个事务里,这时就有可能需要用到JTA事务了)绑定;
- managed:Hibernate委托程序来管理Session对象的生命周期。
我们之前一直所使用的都是第三种方式,即通过程序获取一个Session对象,然后使用它,最后关闭它,即session.close()。在实际开发中我们一般使用的是前两种,但由于第二种方式是基于分布式数据库而言的,所以在此主要介绍关于本地线程绑定Session的这种方式。你要是想使用这种方式在Hibernate中解决Service层的事务管理,那么就需要在hibernate.cfg.xml核心配置文件中添加如下配置:
然后,通过SessionFactory的getCurrentSession()方法获得与本地线程绑定的Session对象,这样一来,咱的HibernateUtils工具类就要修改为:
1 | package com.meimeixia.hibernate.utils; |
最后,我们来编写程序测试当前与线程绑定的Session。
1 | package com.meimeixia.hibernate.demo01; |
还有人不相信此时Session关闭会报错,你就试着关闭一下嘛!看会不会报下面的错:
报错的原因:使用getCurrentSession方法获取的是与线程绑定的Session对象,在事务关闭(提交)时,Session对象就也被close掉了,简单说,就不需要我们再手动close掉Session对象了。
Query
你可从度娘上可看到这样的文字:
我们主要通过Query完成查询操作,通过Query即可以执行HQL语句,如下:
1 | Query query = session.createQuery("HQL语句"); |
又可以执行本地SQL语句:
1 | SQLQuery sqlQuery = session.createSQLQuery("本地SQL语句"); |
温馨提示:SQLQuery是Query的子类。
查询所有操作——使用HQL
我们这儿在com.meimeixia.hibernate.demo01包下创建一个单元测试类——TestQuery.java。使用HQL语句完成查询所有客户的操作,代码如下:
1 | package com.meimeixia.hibernate.demo01; |
条件查询
条件查询可以使用where关键字。例如,查询姓王的客户。
虽然我们可以查询出来,但我们有没有想过姓王的客户即使查出来也只有一个呢,我们有必要把它放在List集合中吗?如果查询结果可以保证就是唯一的,那么我们可以使用Query的uniqueResult()方法来得到一个单独对象。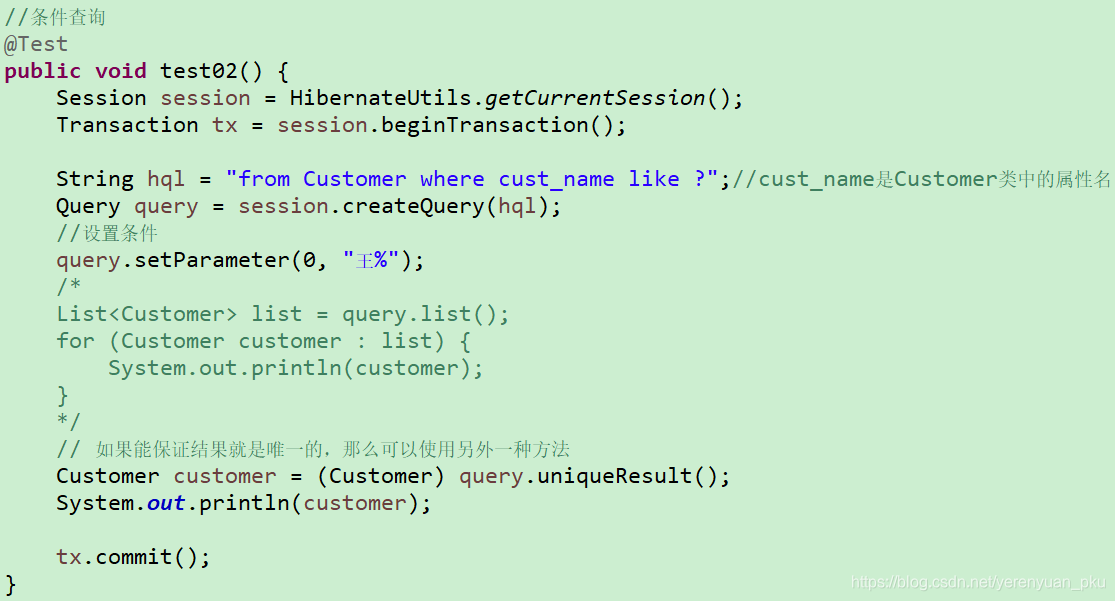
分页查询
在执行分页查询时,我们试着向cst_customer表中插入100条记录。
接下来,就来分页查询,如果说一页显示10条记录,但我们要得到第二页的数据,咋办?
Criteria
你可从度娘上可看到这样的文字:
首先我要想使用Criteria,必须得到Criteria,可这么做:
1 | Criteria criteria = session.createCriteria(Xxx.class); |
查询所有
例,查询所有客户。
1 | package com.meimeixia.hibernate.demo01; |
条件查询
例,查询姓渣并且客户信息来源为b站的客户。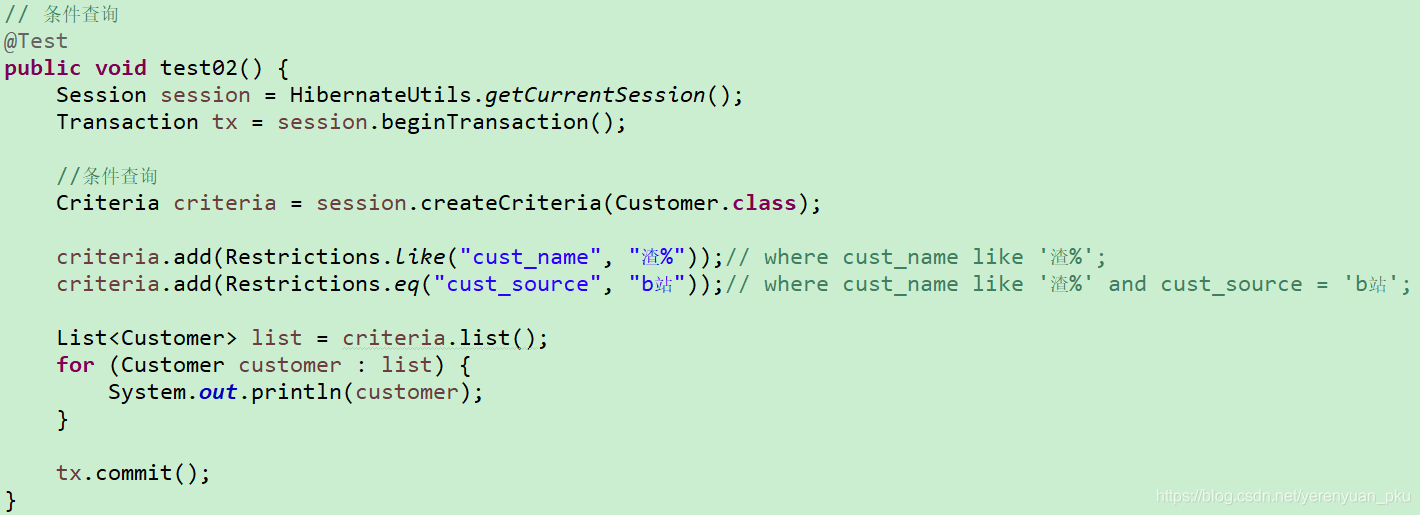
分页查询
分页查询操作与Query的方法一样。如果说一页显示10条记录,但我们要得到第二页的数据,咋办?
小结
我们使用Criteria可以更加面向对象地去操作,它非常适合进行多条件组合查询,但我感觉没什么鸟用!
Hibernate的一对多关联映射
创建数据库和表
这里我们以客户(Customer)与联系人(linkMan)为例来讲解Hibernate关联映射中的一对多关联关系,因此我们要创建一个数据库,并在该数据库下新建两张表——客户表和联系人表,这里笔者使用的数据库是MySQL。
1 | create database hibernate_demo03; |
创建实体
在src目录下创建一个com.meimeixia.hibernate.domain包,并在该包下创建两个实体类,如下:
客户类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74package com.meimeixia.hibernate.domain;
import java.util.HashSet;
import java.util.Set;
/**
* 客户的实体
* @author liayun
*
*/
public class Customer {
private Long cust_id;
private String cust_name;
private String cust_source;
private String cust_industry;
private String cust_level;
private String cust_phone;
private String cust_mobile;
//通过ORM方式表示:一个客户对应多个联系人
//这儿放置的是多的一方的集合。Hibernate默认使用的是Set集合。
private Set<LinkMan> linkMans = new HashSet<LinkMan>();
public Long getCust_id() {
return cust_id;
}
public void setCust_id(Long cust_id) {
this.cust_id = cust_id;
}
public String getCust_name() {
return cust_name;
}
public void setCust_name(String cust_name) {
this.cust_name = cust_name;
}
public String getCust_source() {
return cust_source;
}
public void setCust_source(String cust_source) {
this.cust_source = cust_source;
}
public String getCust_industry() {
return cust_industry;
}
public void setCust_industry(String cust_industry) {
this.cust_industry = cust_industry;
}
public String getCust_level() {
return cust_level;
}
public void setCust_level(String cust_level) {
this.cust_level = cust_level;
}
public String getCust_phone() {
return cust_phone;
}
public void setCust_phone(String cust_phone) {
this.cust_phone = cust_phone;
}
public String getCust_mobile() {
return cust_mobile;
}
public void setCust_mobile(String cust_mobile) {
this.cust_mobile = cust_mobile;
}
public Set<LinkMan> getLinkMans() {
return linkMans;
}
public void setLinkMans(Set<LinkMan> linkMans) {
this.linkMans = linkMans;
}
}联系人类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85package com.meimeixia.hibernate.domain;
/**
* 联系人的实体
* @author liayun
*
*/
public class LinkMan {
private Long lkm_id;
private String lkm_name;
private String lkm_gender;
private String lkm_phone;
private String lkm_mobile;
private String lkm_email;
private String lkm_qq;
private String lkm_position;
private String lkm_memo;
//通过ORM方式来表示:一个联系人只能属于某一个客户
//这儿放置的是一的一方的对象
private Customer customer;
public Long getLkm_id() {
return lkm_id;
}
public void setLkm_id(Long lkm_id) {
this.lkm_id = lkm_id;
}
public String getLkm_name() {
return lkm_name;
}
public void setLkm_name(String lkm_name) {
this.lkm_name = lkm_name;
}
public String getLkm_gender() {
return lkm_gender;
}
public void setLkm_gender(String lkm_gender) {
this.lkm_gender = lkm_gender;
}
public String getLkm_phone() {
return lkm_phone;
}
public void setLkm_phone(String lkm_phone) {
this.lkm_phone = lkm_phone;
}
public String getLkm_mobile() {
return lkm_mobile;
}
public void setLkm_mobile(String lkm_mobile) {
this.lkm_mobile = lkm_mobile;
}
public String getLkm_email() {
return lkm_email;
}
public void setLkm_email(String lkm_email) {
this.lkm_email = lkm_email;
}
public String getLkm_qq() {
return lkm_qq;
}
public void setLkm_qq(String lkm_qq) {
this.lkm_qq = lkm_qq;
}
public String getLkm_position() {
return lkm_position;
}
public void setLkm_position(String lkm_position) {
this.lkm_position = lkm_position;
}
public String getLkm_memo() {
return lkm_memo;
}
public void setLkm_memo(String lkm_memo) {
this.lkm_memo = lkm_memo;
}
public Customer getCustomer() {
return customer;
}
public void setCustomer(Customer customer) {
this.customer = customer;
}
}创建映射配置文件
创建映射配置文件
实体类创建完成之后,再在com.meimeixia.hibernate.domain包下分别创建这两个类的映射配置文件。
Customer.hbm.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
<hibernate-mapping>
<class name="com.meimeixia.hibernate.domain.Customer" table="cst_customer">
<!-- 建立OID与主键的映射 -->
<id name="cust_id" column="cust_id">
<generator class="native"></generator>
</id>
<!-- 建立类中的普通属性和数据库表中字段的映射 -->
<property name="cust_name" column="cust_name" />
<property name="cust_source" column="cust_source" />
<property name="cust_industry" column="cust_industry" />
<property name="cust_level" column="cust_level" />
<property name="cust_phone" column="cust_phone" />
<property name="cust_mobile" column="cust_mobile" />
<!-- 配置一对多的映射:放置的是多的一方的对象的集合 -->
<!--
set标签:
1. name:多的一方的对象集合的属性名称
-->
<set name="linkMans">
<!--
key标签:
1. column:多的一方的外键的名称
-->
<key column="lkm_cust_id"></key>
<!--
one-to-many标签:
1. class:多的一方的类的全路径
-->
<one-to-many class="com.meimeixia.hibernate.domain.LinkMan" />
</set>
</class>
</hibernate-mapping>LinkMan.hbm.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
<hibernate-mapping>
<class name="com.meimeixia.hibernate.domain.LinkMan" table="cst_linkman">
<!-- 建立OID与主键的映射 -->
<id name="lkm_id" column="lkm_id">
<generator class="native"></generator>
</id>
<!-- 建立类中的普通属性和数据库表中字段的映射 -->
<property name="lkm_name" />
<property name="lkm_gender" />
<property name="lkm_phone" />
<property name="lkm_mobile" />
<property name="lkm_email" />
<property name="lkm_qq" />
<property name="lkm_position" />
<property name="lkm_memo" />
<!-- 配置多对一的关系:放置的是一的一方的对象 -->
<!--
many-to-one标签:
1. name : 一的一方的对象的属性名称
2. class : 一的一方的类的全路径
3. column : 在多的一方的表的外键名称
-->
<many-to-one name="customer" class="com.meimeixia.hibernate.domain.Customer" column="lkm_cust_id"></many-to-one>
</class>
</hibernate-mapping>创建核心配置文件
在src目录下新建一个hibernate.cfg.xml,其内容如下:
1 |
|
温馨提示:在核心配置文件中,一定记住得引入映射配置文件,也就是告诉Hibernate的核心配置文件要加载哪几个映射配置文件。
引入工具类
在src目录下新建一个com.meimeixia.hibernate.utils包,并在该包下创建一个名称叫HibernateUtils的工具类,专门用于获取Session对象。
1 | package com.meimeixia.hibernate.utils; |
编写测试类测试双向关联保存
现在我们来测试保存的操作,在src目录下创建一个com.meimeixia.hibernate.demo01包,并在该包下编写一个OneToManyTest单元测试类,然后在该类中编写一个用于测试保存的操作,如下:
1 | package com.meimeixia.hibernate.demo01; |
运行以上demo01方法,就能向客户表中插入2条记录,向联系人表中插入3条记录。其实上面测试保存的操作就是一种双向关联关系,如果做的是双向的关联,而没有用cascade去做级联,那么就存在一个浪费的环节
ibernate的一对多相关操作
一对多的关系,只保存一边是否可以?
顺其自然地,我们就会想可不可以只保存客户或只保存联系人就能完成保存的操作呢?答案是不言而喻的不可以。下面我就来简单地讲讲。
还是在双向关联关系的情况下,我们只保存一边,也就是说你要么只保存客户,要么只保存联系人,可以预想到的是我们可能会这样写代码:
1 | //一对多的关系,只保存一边是否可以? |
运行以上方法,会发现报了一个瞬时态对象异常,即持久态对象关联了一个瞬时态对象。
出现问题,就要着手解决,那又该怎么解决呢?这就引出了下面我要讲的一对多的级联操作。
一对多的级联操作
什么叫做级联呢?级联指的是操作某一个对象的时候,是否会同时操作其关联的对象。我们一定要注意:级联是有方向性的,也就是说操作一的一方的时候,是否操作到多的一方,或者操作多的一方的时候,是否操作到一的一方。
级联保存或更新
级联是有方向性的,现在我们要做的是保存客户,然后去级联保存联系人。由于现在操作的主体对象是客户对象,所以就需要在客户的映射文件中进行配置。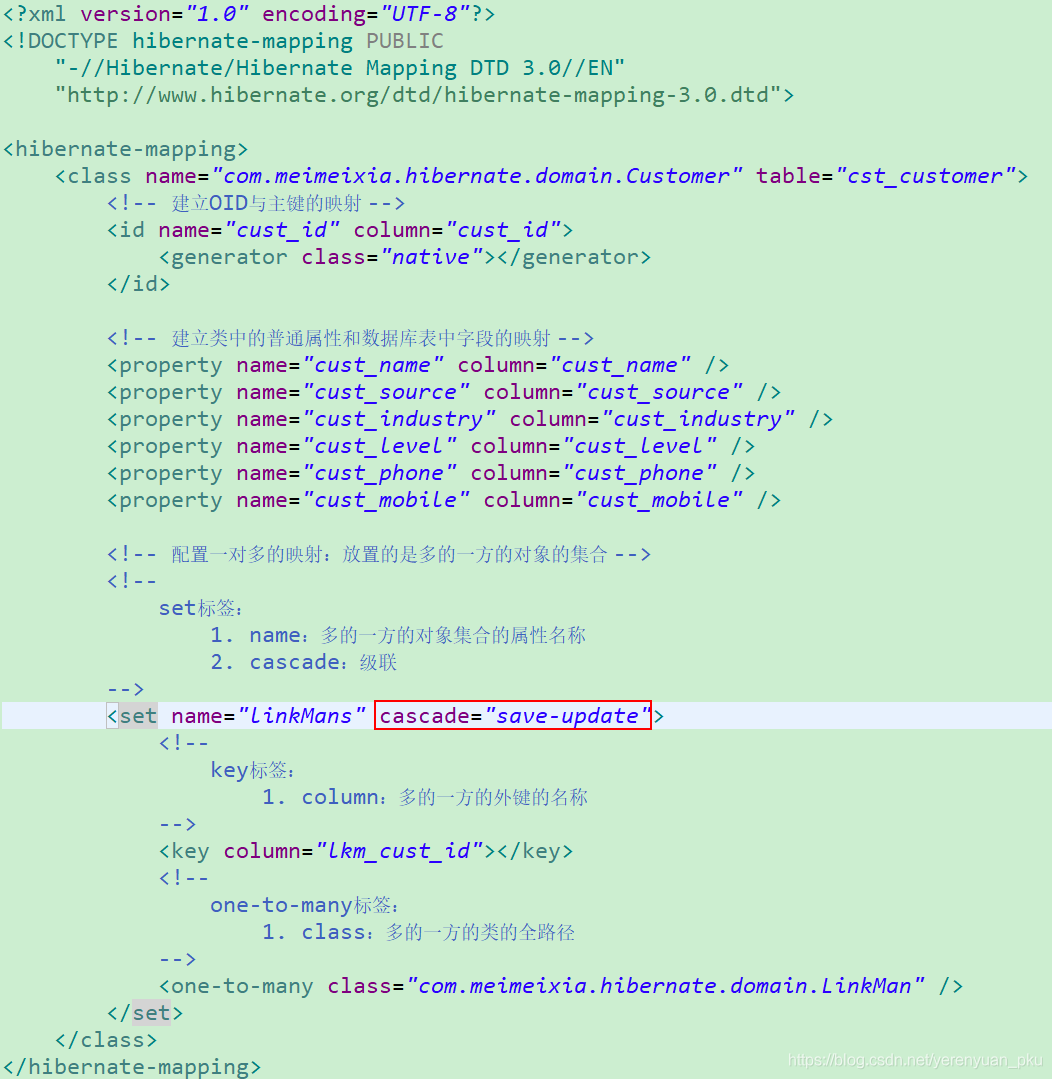
这时,运行以下测试方法,就能在保存客户时顺带自动保存联系人。
1 | /** |
我们又想要在保存联系人时,保存客户,那又该怎么做呢?答案是不言而喻的,用屁股想都能知道,现在操作的主体对象是联系人对象,所以就需要在联系人的映射文件中进行配置。
这时,运行以下测试方法,就能在保存联系人时顺带自动保存客户。
1 | /** |
级联删除
啥是级联删除呢?级联删除指的是在删除一方的时候,同时会将另一方的数据也一并删除掉。现在我们有这样一个需求:当我们删除一个客户时,应该将客户关联的联系人也删除掉。由于删除的主体对象是客户对象,所以就需要在客户的映射文件中进行配置。
此时,运行以下测试方法,就能在删除客户时,然后去级联删除联系人。
1 | /** |
如果要是在客户的映射文件中没有设置级联删除呢?那会是什么情况呢?默认情况是修改了联系人的外键(即将联系人的外键置为null),然后删除了客户,看Eclipse控制台中Hibernate向数据库发送的SQL语句便知。
又有这样一个需求:当我们删除一个联系人时,应该将联系人关联的客户也删除掉,这种情况在实际开发中基本不会遇到。由于现在删除的主体对象是联系人对象,那么就需要在联系人的映射文件中进行配置。
此时,运行以下测试方法,就能在删除联系人时,然后去级联删除客户。
1 | /** |
delete-orphan用法
delete-orphan:字面意思是删除孤儿,其实指的是删除与当前对象解除关系的对象。为了说明delete-orphan到底是个啥玩意,我们可以这样子做,先别在双方的映射配置文件中设置级联操作,然后运行以下测试方法。
1 | //演示delete-orphan |
发现归属于2号客户的3号联系人并没有被删除掉,只是将3号联系人的外键置为了null。
如果想起到我们预期的效果,可以在客户类的映射文件中进行配置。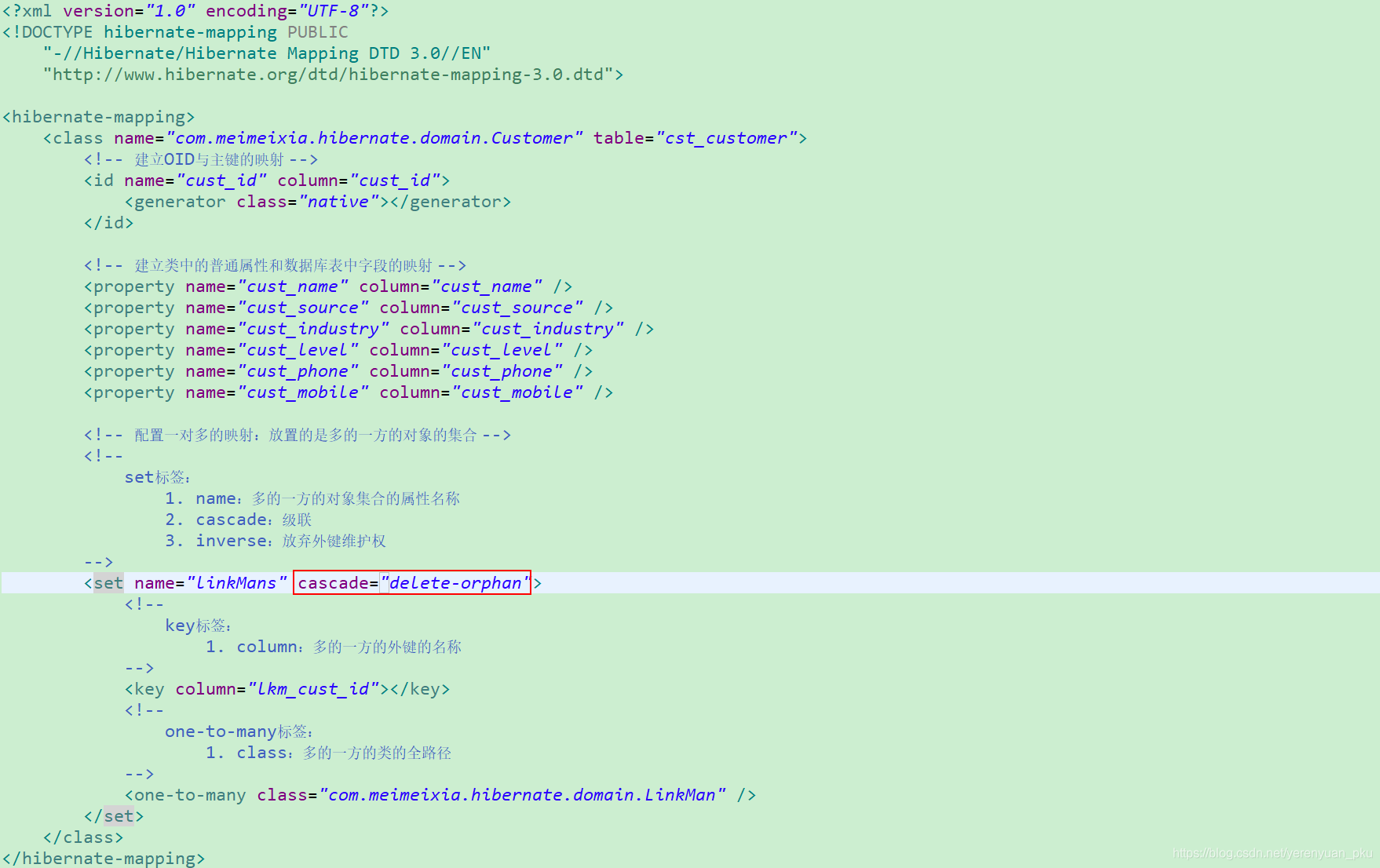
此时,再次运行tesDeleteOrphan()测试方法,那可真就将归属于2号客户的3号联系人删除掉了。
cascade总结
使用cascade可以完成级联操作,它的常用可取值:
- none:这是一个默认值;
- save-update:当我们配置它后,底层使用save、update或saveOrUpdate完成操作时,会级联保存临时对象,如果是游离对象,会执行update;
- delete:级联删除;
- delete-orphan:删除与当前对象解除关系的对象;
- all:它包含了save-update、delete操作;
- all-delete-orphan:它包含了delete-orphan与all操作。
一对多关系的对象导航
下面来看看一对多关系的对象导航问题,如图: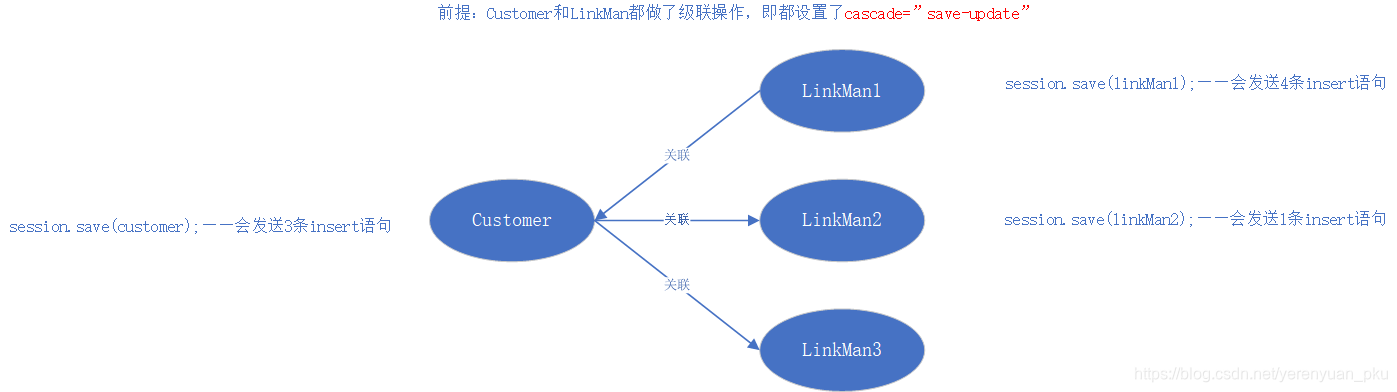
接着,我们来编写代码进行演示,在OneToManyTest单元测试类编写如下测试方法:
1 | /** |
运行以上方法,你可以在Eclipse控制台查看Hibernate向数据库到底发送了几条insert语句。
一对多设置了双向关联会产生多余的SQL语句
我们在开发中有时要配置双向关联,这样就可以通过任意一方来操作对方,但在写操作代码时,应尽量要进行单向关联,因为这样可以尽量减少资源浪费。在前面编写测试类测试双向关联保存那一小节中,我讲到存在一个资源浪费的问题,在这一节中我就会细讲一下是怎么回事。
回到最初编写测试类测试双向关联保存的位置(双方都没配置级联),如果像那样运行demo01方法,那么Eclipse控制台会打印如下SQL语句:
发现有6条update语句,为什么会这样呢?原因非常简单,我们现在这个操作,是做了一个双向关联,那么客户和联系人都会去维护lkm_cust_id这个外键,也就是说当我们插入联系人的时候,lkm_cust_id是没值的,因为还没有Customer,所以它插入的是一个null值。当我们插入完联系人以后,再去插入客户,客户有了,我们就需要对联系人里面的lkm_cust_id去修改,所以就会出现这样一种情况。
在双向关联中,会产生多余的update语句,这个存在虽然不影响我们的程序运行,但是会影响性能,因为它在浪费资源。所以在写操作代码时,尽量要进行单向关联,但如果我们非得进行双向关联呢?那又该怎么减少资源浪费呢?这时我们可以使用inverse属性来设置,双向关联时由哪一方来维护表与表之间的关系。通常我们都会在多的一方维护关联关系,也就是说使一的一方放弃外键维护权,所以最好由联系人来维护双向关联关系,这样子的话,客户的映射配置文件应修改为:
- inverse的值如果为true,代表由对方来维护外键;
- inverse的值如果为false,代表由本方来维护外键。
关于inverse的取值有这样一个原则:外键在哪一个表中,我们就让哪一方来维护外键。就这样简简单单修改之后,再次运行demo01方法,Eclipse控制台会打印如下SQL语句:
区分cascade和inverse
很多人初次学Hibernate的时候,会很容易把cascade和inverse搞混,包括笔者也是,但它俩之间有本质的区别,压根就不是一个东西。
- cascade:控制这个对象的关联对象;
- inverse:控制一的一方能不能去维护这个外键,也就是说管不管这个外键?
咱也不说啥,用事实说话。我们可以这样子做,首先在客户的映射配置文件中设置级联操作,并且放弃外键维护权。
联系人的映射配置文件中啥也不做,内容如下:
然后,我们只设置单向关联关系,即客户关联联系人,联系人就不要关联客户了,运行以下测试方法,会有什么效果呢?
1 | /** |
此时,客户会插入到数据库表中,联系人也会插入到数据库表中,但是外键为null。为啥呢?因为现在一的一方(即客户)已经放弃外键的维护权了,而且你又只是设置单向关联关系,那当然联系人表中的外键为null。这也从另外一个角度说明,如果只设置了单向关联关系(一的一方关联多的一方),那么最好是不要放弃外键的维护权。
多对多关联映射
环境搭建
创建表
这里我们以用户(User)与角色(Role)为例来讲解Hibernate关联映射中的多对多关联关系,因此我们要在数据库下新建三张表——用户表、角色表以及中间表,这里笔者使用的数据库是MySQL。
1 | CREATE TABLE `sys_user` ( |
创建实体
在src目录下的com.meimeixia.hibernate.domain包中创建两个实体类,如下:
用户的实体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61package com.meimeixia.hibernate.domain;
import java.util.HashSet;
import java.util.Set;
/**
* 用户的实体
* @author liayun
*
*/
public class User {
private Long user_id;
private String user_code;
private String user_name;
private String user_password;
private String user_state;
//如何设置多对多的关系,即表示一个用户可以选择多个角色?
//放置的是角色的集合
private Set<Role> roles = new HashSet<Role>();
public Long getUser_id() {
return user_id;
}
public void setUser_id(Long user_id) {
this.user_id = user_id;
}
public String getUser_code() {
return user_code;
}
public void setUser_code(String user_code) {
this.user_code = user_code;
}
public String getUser_name() {
return user_name;
}
public void setUser_name(String user_name) {
this.user_name = user_name;
}
public String getUser_password() {
return user_password;
}
public void setUser_password(String user_password) {
this.user_password = user_password;
}
public String getUser_state() {
return user_state;
}
public void setUser_state(String user_state) {
this.user_state = user_state;
}
public Set<Role> getRoles() {
return roles;
}
public void setRoles(Set<Role> roles) {
this.roles = roles;
}
}角色的实体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46package com.meimeixia.hibernate.domain;
import java.util.HashSet;
import java.util.Set;
/**
* 角色的实体
* @author liayun
*
*/
public class Role {
private Long role_id;
private String role_name;
private String role_memo;
//如何设置多对多的关系,即表示一个角色被多个用户所选择?
//放置的是用户的集合
private Set<User> users = new HashSet<User>();
public Long getRole_id() {
return role_id;
}
public void setRole_id(Long role_id) {
this.role_id = role_id;
}
public String getRole_name() {
return role_name;
}
public void setRole_name(String role_name) {
this.role_name = role_name;
}
public String getRole_memo() {
return role_memo;
}
public void setRole_memo(String role_memo) {
this.role_memo = role_memo;
}
public Set<User> getUsers() {
return users;
}
public void setUsers(Set<User> users) {
this.users = users;
}
}创建映射配置文件
实体类创建完成之后,再在com.meimeixia.hibernate.domain包下分别创建这两个类的映射配置文件。
User.hbm.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
<hibernate-mapping>
<class name="com.meimeixia.hibernate.domain.User" table="sys_user">
<!-- 建立OID与主键的映射 -->
<id name="user_id" column="user_id">
<generator class="native"></generator>
</id>
<!-- 建立类中的普通属性与字段的映射 -->
<property name="user_code" column="user_code" />
<property name="user_name" column="user_name" />
<property name="user_password" column="user_password" />
<property name="user_state" column="user_state" />
<!-- 建立与角色的多对多的映射关系 -->
<!--
set标签:
1. name:对方的集合的属性名称
2. table:多对多的关系需要使用中间表,放置的是中间表的名称
-->
<set name="roles" table="sys_user_role">
<!--
key标签:
1. column:放置的是当前的对象对应的中间表的外键名称
-->
<key column="user_id"></key>
<!--
many-to-many标签:
1. class:对方的类的全路径
2. column:对方的对象在对应的中间表中的外键名称
-->
<many-to-many class="com.meimeixia.hibernate.domain.Role" column="role_id"></many-to-many>
</set>
</class>
</hibernate-mapping>Role.hbm.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
<hibernate-mapping>
<class name="com.meimeixia.hibernate.domain.Role" table="sys_role">
<!-- 建立OID与主键的映射 -->
<id name="role_id" column="role_id">
<generator class="native"></generator>
</id>
<!-- 建立类中的普通属性与数据库表中字段的映射 -->
<property name="role_name" column="role_name" />
<property name="role_memo" column="role_memo" />
<!-- 建立与用户的多对多的映射关系 -->
<!--
set标签:
1. name:对方的集合的属性名称
2. table:多对多的关系需要使用中间表,放置的是中间表的名称
-->
<set name="users" table="sys_user_role">
<!--
key标签:
1. column:放置的是当前的对象对应的中间表的外键名称
-->
<key column="role_id"></key>
<!--
many-to-many标签:
1. class:对方的类的全路径
2. column:对方的对象在对应的中间表中的外键名称
-->
<many-to-many class="com.meimeixia.hibernate.domain.User" column="user_id"></many-to-many>
</set>
</class>
</hibernate-mapping>在核心配置文件中引入映射配置文件

编写测试类测试双向关联保存
现在我们来测试保存的操作,在src目录下创建一个com.meimeixia.hibernate.demo02包,并在该包下编写一个ManyToManyTest单元测试类,然后在该类中编写一个用于测试保存的操作,如下:
1 | package com.meimeixia.hibernate.demo02; |
运行以上demo01方法,可以看到会报如下异常。
为啥呀!这是因为如果多对多建立了双向的关联关系,那么必须有一方放弃外键维护。问题又来了,通常让哪一方放弃呢?一般是让被动方去放弃外键的维护权。在这里,被动方到底是哪个呢?你可以认为是角色的一方。所以,我们应在角色的映射配置文件中进行设置。
这时,再次运行demo01方法,就能运行成功了。
Hibernate的多对多相关操作
多对多的关系,只保存一边是否可以?
在双向关联关系的情况下,我们只保存一边,也就是说你要么只保存用户,要么只保存角色,是否可行?可以预想到的是我们可能会这样写代码:
1 | /** |
运行以上方法,会发现报了一个瞬时态对象异常,即持久态对象关联了一个瞬时态对象。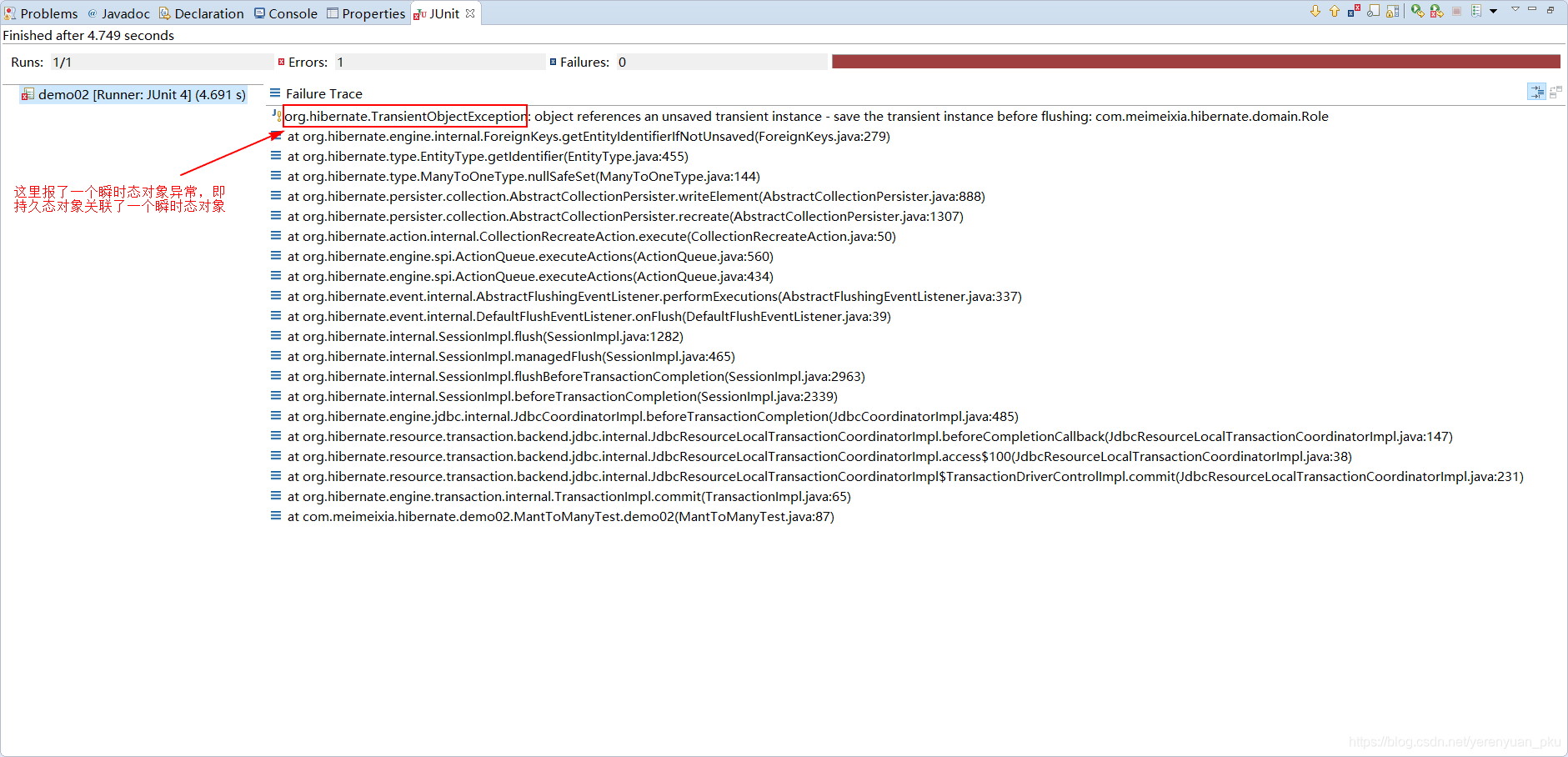
出现问题,就要着手解决,那又该怎么解决呢?这就引出了下面我要讲的多对多的级联操作。
多对多的级联操作
级联保存或更新
级联是有方向性的,现在我们要做的是保存用户,然后去级联保存角色。由于现在操作的主体对象是用户对象,所以就需要在用户的映射文件中进行配置。
这时,运行以下测试方法,就能在保存用户时顺带自动保存角色。
1 | /** |
我们又想要在保存角色时,保存用户,那又该怎么做呢?答案是不言而喻的,用屁股想都能知道,现在操作的主体对象是角色对象,所以就需要在角色的映射文件中进行配置。
温馨提示:由于现在外键是由角色这方来维护的,所以用户那方要放弃外键的维护权,也就说用户的映射文件要这样配置。
这时,运行以下测试方法,就能在保存角色时顺带自动保存用户。
1 | /** |
级联删除(基本上用不上)
现在我们有这样一个需求:当我们删除一个用户时,应该将用户关联的角色也删除掉。由于删除的主体对象是用户对象,所以就需要在用户的映射文件中进行配置。
此时,运行以下测试方法,就能在删除用户时,然后去级联删除角色。
1 | /** |
又有这样一个需求:当我们删除一个角色时,应该将角色关联的用户也删除掉。由于现在删除的主体对象是角色对象,那么就需要在角色的映射文件中进行配置。
温馨提示:如果你现在也在用户的映射文件中设置级联删除,就像下面这样,
就是说现在双方都设置了级联删除,那么就很可能会出现严重的后果。我现在是要删除1号角色的,照理来说它就会把1号角色所关联的用户(即1号用户)删除掉,但是由于我在双方都设置了级联删除,尼玛的,全JB删除光了,这是咋鸡儿回事呢?因为现在删除了1号角色,所以它会连带地删除1号角色所关联的用户,1号角色所关联的用户又关联了其他的角色,就又会删除掉所关联的角色,所关联的角色又JB关联了其他用户,就又会删除掉其他用户…感觉没完没了啊!
所以,现在为了要测试在删除角色时,然后去级联删除用户,最好是只在角色的映射文件设置级联删除,不要在用户的映射文件中也设置级联删除了。这个时候,再运行以下测试方法,就能在删除角色时,然后去级联删除用户。
1 | /** |
多对多的其他的操作
首先做下准备工作,运行demo01方法,让数据库表中初始化一些数据,如下图所示。
给用户选择角色
例,给1号用户多选择一个3号角色。
1 | /** |
运行以上测试方法,就能给1号用户多选择一个3号角色。
给用户改选角色
例,给2号用户将原有的3号角色改为1号角色。
1 | /** |
运行以上测试方法,就能给2号用户将原有的3号角色改为1号角色。
给用户删除角色
例,给2号用户删除1号角色。
1 | /** |
运行以上测试方法,就能给2号用户删除1号角色。
Hibernate检索方式的概述
归纳起来可分为五种。
- OID检索方式:按照对象的OID来检索对象;
- 对象导航图检索方式:根据已加载的对象导航到其它对象;
- HQL检索方式:使用面向对象的HQL查询语言;
- QBC检索方式:使用QBC(Query by Criteria)API来检索对象,这种API封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口;
- 本地SQL检索方式:使用本地数据库的SQL查询语句。
Hibernate中的五种检索方式
OID检索方式
这种方式用老多遍了,我都懒得说了。所谓OID检索,就是Hibernate根据对象的OID(主键)进行检索。在Hibernate中,我们可通过get或load方法根据OID来查询指定的对象。
使用get方法
1
2Customer customer = session.get(Customer.class, 1l);
1使用load方法
1
2Customer customer = session.load(Customer.class, 1l);
1对象导航图检索方式
所谓的对象导航图检索方式就是通过在Hibernate中进行映射关系,然后在Hibernate操作时,可以通过导航方式得到其关联的持久化对象信息。说得更容易理解一点就是:对象导航图检索方式就是Hibernate根据一个已经查询到的对象,获得其关联对象的一种查询方式。
1 | LinkMan linkMan = session.get(LinkMan.class, 1l); |
或者
1 | Customer customer = session.get(Customer.class, 2l); |
HQL检索方式
HQL是我们在Hibernate中最常用的一种检索方式。HQL(Hibernate Query Language)提供了更加丰富灵活、更为强大的查询能力,因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装。完整的HQL语句形式如下:
1 | select/update/delete ...... from ...... where ...... group by ...... having ...... order by ...... asc/desc |
其中的update/delete为Hibernate3中所新添加的功能,可见HQL查询非常类似于标准SQL查询。HQL检索的基本步骤:
- 得到Session;
- 编写HQL语句;
- 通过
session.createQuery(HQL语句)创建一个Query对象; - 为Query对象设置条件参数;
- 执行list()方法查询所有,它返回的是一个List集合或者执行uniqueResult()方法返回一个唯一的查询结果。
基本检索
基本检索就是from 类名,from是关键字,后面是类名,关键字是不区分大小写的,但是类名是区分的。以码明示,在HQLTest单元测试类中编写如下单元测试方法:
为了更加方便在Eclipse控制台看到打印的结果,我们最好在Customer类中重写toString()方法。
温馨提示:SQL中支持*号的写法,例如select * from cst_customer;,但是在HQL中是不支持这种写法的。
别名检索
在写HQL查询语句的时候,还能给类起个别名,所以,你可以像下面这样写代码。
1 | /** |
除此之外,你还能这样写你的代码。
排序检索
现在我们的需求是查询客户时,根据客户的ID进行升序排序。以码明示,在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
温馨提示:HQL排序检索时,默认是升序排列,跟SQL里面的排序一样,升序使用的是ASC,降序使用的是DESC。所以,如果查询客户时,要根据客户的ID进行降序排序,那么就要这样写代码了。
1 | /** |
条件检索
我首先来讲根据位置来绑定HQL语句参数的条件检索。如果想要查询名称叫张小敬的客户,那么你有可能在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
在上面的代码中,也只是设置了一个条件,那如果要设置多个条件呢,该咋设置?例如,现在想要查询姓张并且客户信息来源是知乎的客户,那么你有可能会在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
接着我来讲讲根据名称来绑定HQL语句参数的条件检索。如果现在还是想要查询姓张并且客户信息来源是知乎的客户,那么以上demo05方法应修改为如下。
1 | /** |
分页检索
假设现在我们的需求是查询联系人时,每页显示10条记录,但要得到第二页的数据,那么你有可能在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
分组统计检索
先看我们的第一个需求:统计一共有多少个客户。以码明示,在HQLTest单元测试类中编写如下单元测试方法:
再看我们的第二个需求:分组统计每一个客户信息来源有多少客户。此时,以上demo07的方法可能就要修改为:

如果查询增加一点难度,想要分组统计每一个客户信息来源有多少客户,并且客户人数至少要是2人,要想解决这个需求,那么以上demo07的方法可能就要修改为:
其他一些聚合函数,例如max()、min()、avg()以及sum()的使用方法也就和count()一样,在此并不过多赘述。
投影检索
投影检索就是查询对象的某个或某些属性,而不是全部属性。这儿我也只是主要讲解关于实体类中部分属性的查询,这样我们就可以使用投影检索将部分属性封装到对象中。下面我步步为营地讲解投影检索。
一开始,我们的需求可能是这样的:查询出所有客户的名称,故我们可能会在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
运行以上方法,控制台打印出[张小敬, 鸣太子, 二柱子]这样的字符串,那么可以得出结论:如果只是查询一个列,那么得到的结果便是List<Object>。
接着,我们的需求又可能会变成这样:查询所有客户的名称和客户信息来源。故可将以上demo08方法改为:
1 | /** |
从以上方法中可得知,如果是查询多列,那么得到的结果是List<Object[]>。
最后,我们可能想到使用投影查询将查询的结果封装到Customer对象中。故可将以上demo08方法改为:

温馨提示:我们必须在Customer类中提供对应属性的构造方法,也要有无参数构造。所以,Customer类中的内容就应该是下面这样的。
命名检索
现在我就来讲讲命名检索,我们可以将HQL语句先定义出来,在使用时通过session.getNamedQuery(hqlName);得到一个Query对象,然后再执行检索。那么问题就来了,这个HQL语句到底定义在什么位置呢?如果你有映射配置文件,那么当前的HQL操作是针对哪一个实体进行操作的,就在哪一个实体的映射配置文件中进行声明,声明就像下面这样。
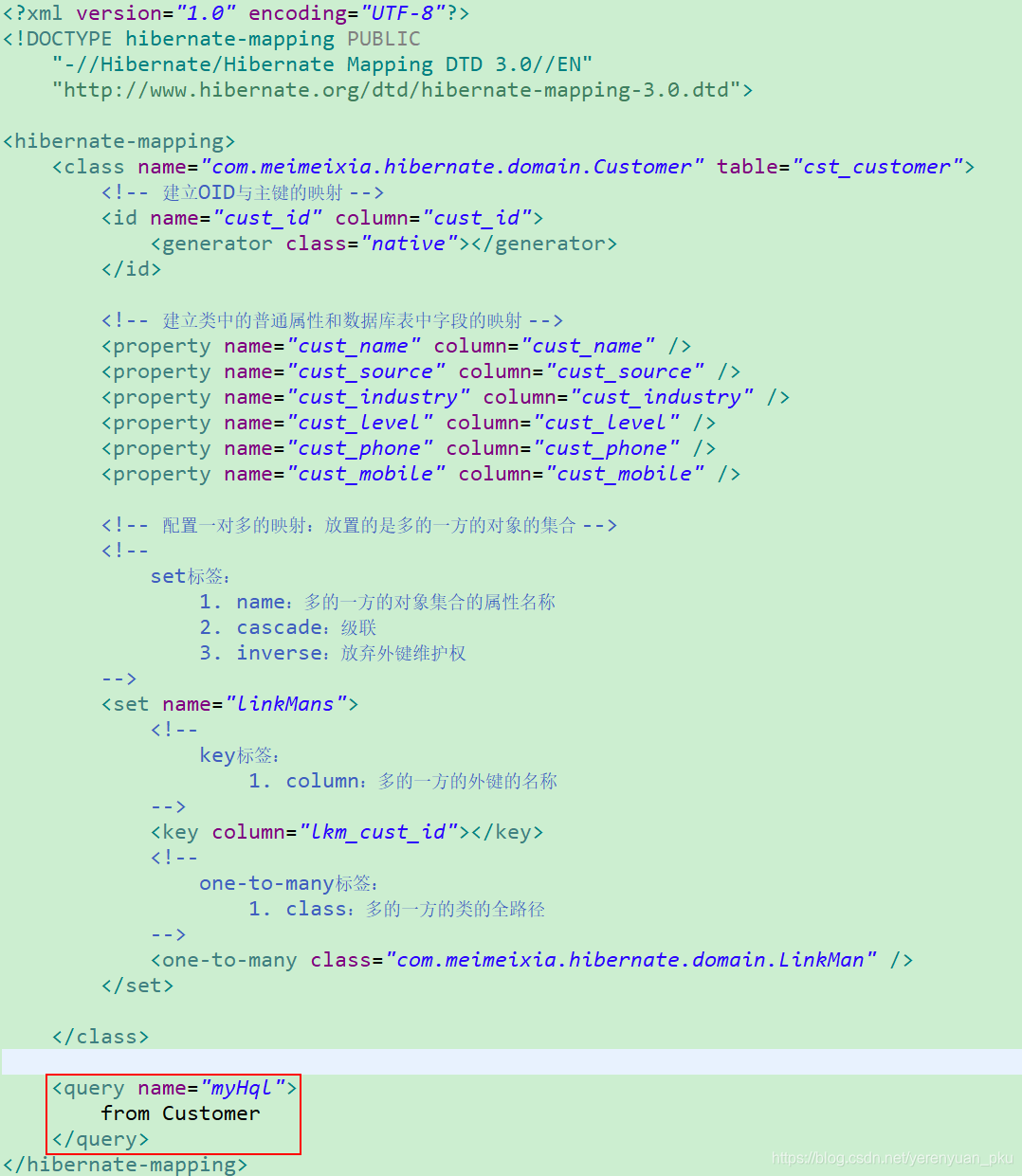
当然了,如果你是使用注解来描述PO类的配置,那么你可以直接在PO类中使用@NamedQuery注解来声明。这又是另外一个话题了,因为我们得会Hibernate的注解开发,之前我们一直都是使用映射配置文件,这儿突然来使用注解进行声明,未免太过唐突,所以,这儿我就不讲解这种方式了。感兴趣的童鞋,可以自己实践实践!
此时我们是准备要查询所有客户的,所以,可以在HQLTest单元测试类中编写如下单元测试方法:
1 | /** |
关于命名查询,我就讲到这里。
QBC检索方式
QBC(Query by Criteria),它是一种更加面向对象的检索方式。使用QBC检索的步骤如下:
- 通过Session的createCriteria方法得到一个Criteria对象,即session.createCriteria();
- 设定条件,每个Criterion实例就代表一个条件,它的获取可以通过Restrictions类提供的静态方法得到,然后可通过Criteria的add方法添加查询条件;
- 调用Criterion的list方法进行查询,即criterion.list()。
基本检索
有一个需求:查询所有的Customer对象。以码明示,在com.meimeixia.hibernate.demo01包下编写一个QBCTest单元测试类,并在该类中编写如下测试方法:
1 | package com.meimeixia.hibernate.demo01; |
排序检索
有这样一个需求:查询客户信息,并根据客户的ID进行排序。以码明示,在QBCTest单元测试类中编写如下测试方法:
1 | /** |
条件检索
有这样一个需求:查询客户信息来源为知乎的客户。以码明示,在QBCTest单元测试类中编写如下测试方法:
1 | /** |
现在又有了这样一个需求:查询姓张并且客户信息来源为知乎的客户。这时,可将QBCTest单元测试类中的demo03方法修改为:
1 | /** |
分页检索
有这样一个需求:查询联系人时,每页显示10条记录,但我们要得到第二页的数据,那么你有可能在QBCTest单元测试类中编写如下单元测试方法:
1 | /** |
统计检索
有这样一个需求:统计客户总数。以码明示,在QBCTest单元测试类中编写如下单元测试方法:
1 | /** |
我想在实际开发中,像这样子的统计检索应该用的不多,使用最多的还要数HQL分组统计检索,可能这种方式比较接近SQL查询,可以直观地让人感受到Hibernate底层向数据库发送了什么样子的SQL查询语句。
离线条件检索
Hibernate框架支持在运行时动态生成查询语句,DetachedCriteria对象可以脱离Session而使用。之前我们在三层架构之间传递用户提交的参数可能是这样的:
但使用离线条件对象进行检索时,情况有可能是这样的:
现在有这样一个需求:查询姓张的客户。以码明示,在QBCTest单元测试类中编写如下单元测试方法:
1 | /** |
本地SQL检索方式
有这样一个需求:查询所有的Customer对象。以码明示,在com.meimeixia.hibernate.demo01包中编写一个SQLTest单元测试类,并在类中编写如下方法:
1 | package com.meimeixia.hibernate.demo01; |
需要说明的是本地SQL查询也支持命名查询。那么问题就来了,这个本地SQL语句到底应定义在什么位置呢?如果你有映射配置文件,那么当前的SQL查询是针对哪一个实体进行操作的,就在哪一个实体的映射配置文件中进行声明,声明就像下面这样。
本地命名SQL还可使用注解来定义,但这里我就不讲了,感兴趣的童鞋,可以自己动手实践实践!
此时我们是准备要查询所有客户的,所以,可以在SQLTest单元测试类中编写如下单元测试方法:
1 |
|
Hibernate中的多表查询
SQL多表查询
SQL的多表查询可分为连接查询和子查询,子查询其实就是SQL嵌套(在这里,它并不是咱的重点,所以我就不展开讲解了),这里我会重点讲解连接查询。
连接查询
连接查询又分为交叉连接(CROSS JOIN)、内连接(INNER JOIN ON)以及外连接。
交叉连接
交叉连接其实是没有实际意义的,它会产生迪卡尔积。例如:
1 | SELECT * FROM cst_customer, cst_linkman; |
内连接
使用内连接,它只能将有关联的数据得到,也就是说内连接查询到的是两张表的公共部分。内连接可分为两种,它们分别是隐式内连接和显示内连接。
隐式内连接
内连接有一种隐式内连接,它使用”逗号”将表分开,使用WHERE来消除迪卡尔积。例如:
1 | SELECT * FROM cst_customer c,cst_linkman l WHERE c.cust_id=l.lkm_cust_id; |
显示内连接
显示内连接如果写全的话,就像下面这样,但是我们应知道INNER是可以省略的。
1 | SELECT * FROM cst_customer c INNER JOIN cst_linkman l ON c.cust_id=l.lkm_cust_id; |
外连接
外连接也可分为两种,它们分别是左外连接(LEFT OUTER JOIN)和右外连接(RIGHT OUTER JOIN)。
左外连接
左外连接是以左表为基准关联数据,说的大白话一点就是它展示的数据只是在左表中有的,右表中没有的不管,也就是说它查询到的是左边表的全部数据以及两张表的公共部分。
左外连接如果写全的话,就像下面这样,但是我们应知道OUTER是可以省略的。
1 | SELECT * FROM cst_customer c LEFT OUTER JOIN cst_linkman l ON c.cust_id=l.lkm_cust_id; |
右外连接
右外连接是以右表为基准关联数据,说的大白话一点就是它展示的数据只是在右表中有的,左表中没有的不管,也就是说它查询到的是右边表的全部数据以及两张表的公共部分。
右外连接如果写全的话,就像下面这样,但是我们应知道OUTER是可以省略的。
1 | SELECT * FROM cst_customer c RIGHT OUTER JOIN cst_linkman l ON c.cust_id=l.lkm_cust_id; |
HQL多表查询
HQL中的多表查询可分为下面几类。
温馨提示:在Hibernate框架中有迫切连接的这一概念,而在SQL中是没有的。
内连接
显示内连接
显示内连接使用的是inner join with。如果是在MySQL中使用显示内连接,SQL语句是咋写的,你还记得吗?
1 | SELECT * FROM cst_customer c INNER JOIN cst_linkman l ON c.cust_id = l.lkm_cust_id; |
但在Hibernate框架中,我们则要这样书写HQL语句,是不是大不同啊!
1 | from Customer c inner join c.linkMans |
为了便于测试,我们可以在com.meimeixia.hibernate.demo01包下编写一个HQLJoinTest单元测试类,并在该类中编写这样的一个测试方法:
1 | package com.meimeixia.hibernate.demo01; |
运行以上demo01方法,Eclipse控制台将打印如下内容:
于是,我们可得出结论:此时,list()方法返回的结果是一个List集合,集合中存放的是Object[],而Object[]中装入的无非是Customer和LinkMan对象。
当然了,我们又可书写这样的HQL语句,使用with再添加一个条件。
1 | from Customer c inner join c.linkMans with c.cust_id=1 |
为了便于进行测试,将HQLJoinTest单元测试类中的demo01方法改为:
1 | // 测试显示内连接 |
运行以上demo01方法,Eclipse控制台将打印如下内容:
隐式内连接
隐式内连接使用频率并不高,它就是一鸡肋。相信在实际开发中,你压根就用不到这种隐式内连接,你都会显示内连接了,还用得着这玩意。
迫切内连接
HQL迫切内连接很少自己手写,迫切内连接使用的是inner join fetch,其实就是在普通的内连接的inner join后面添加一个fetch关键字。迫切内连接是将得到的结果直接封装到PO类中,而内连接得到的是Object[]数组,数组中封装的是PO类对象。下面我们来验证这一点,在HQLJoinTest单元测试类中编写如下方法:
1 | //测试迫切内连接 |
温馨提示:fetch关键字的作用是通知Hibernate,将另一个对象的数据封装到该对象中。在这种情境下,是指将查询出来的LinkMan对象封装到了Customer对象的linkMans集合属性中,你要是不信,可以重写Customer类中的toString()方法,如下图所示。
运行以上demo02方法,Eclipse控制台将打印如下内容: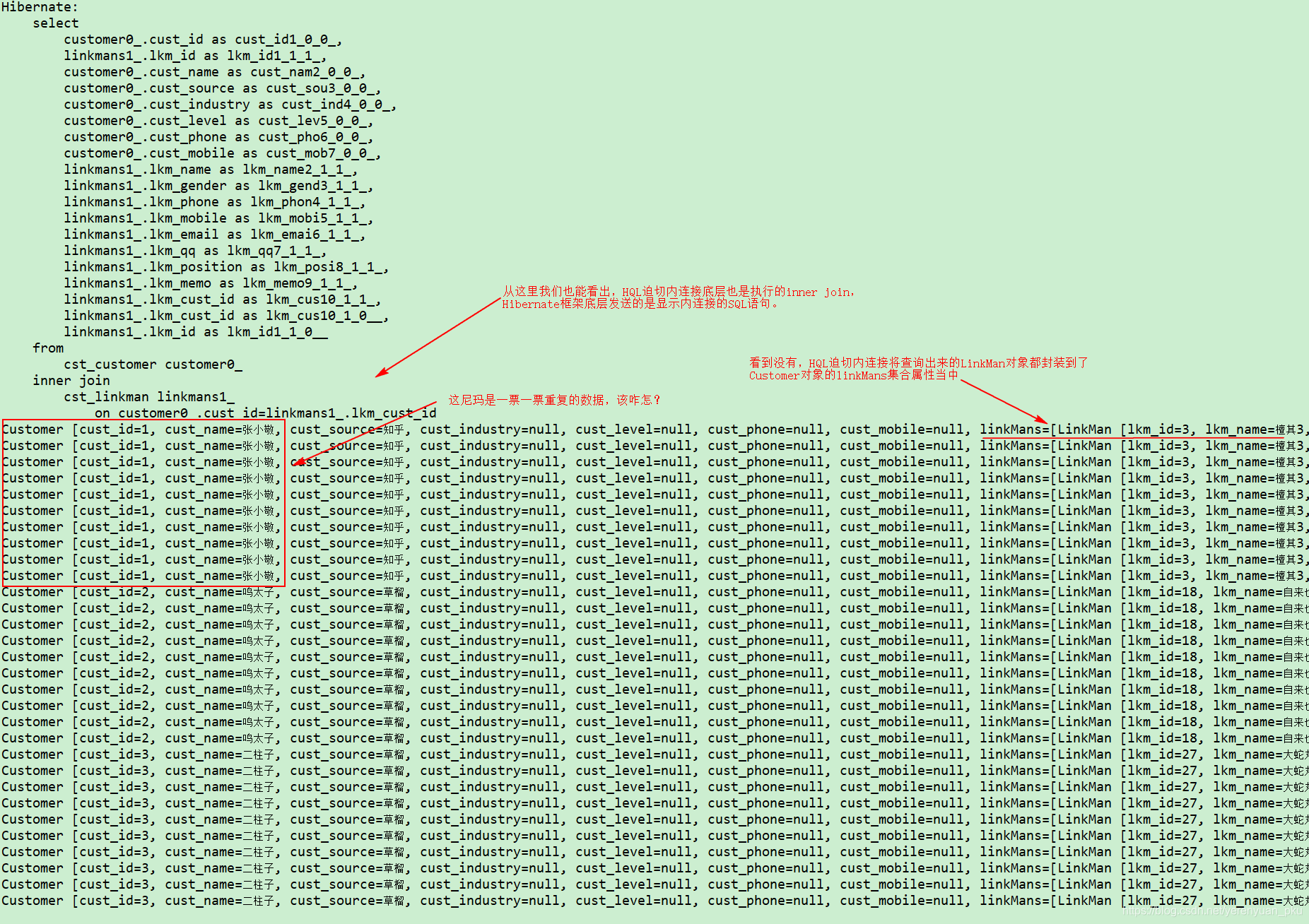
从这里我们也能看出,HQL迫切内连接底层也是执行的inner join,只不过数据结果封装到了对象中了。但问题又来了,我们查询的是两张表的信息,那就会得到合并后的结果,如果是查LinkMan则没问题,但是你要查Customer,Customer就会出现很多重复的数据,这个时候,我们就需要使用关键字——distinct去消除重复了,所以应将demo02方法改为:
1 | //测试迫切内连接 |
再次运行以上demo02方法,Eclipse控制台会打印如下内容:

结论:使用迫切内连接,在结果有可能出现重复时,可以使用distinct关键字来去除重复。
外连接
左外连接
左外连接使用的是left outer join。以码明示,在HQLJoinTest单元测试类中编写如下方法:
1 | //测试左外连接 |
注意:此时,你得重写Customer类中的toString()方法,让其不要包含linkMans属性。接着,运行以上demo03方法,Eclipse控制台将打印如下内容。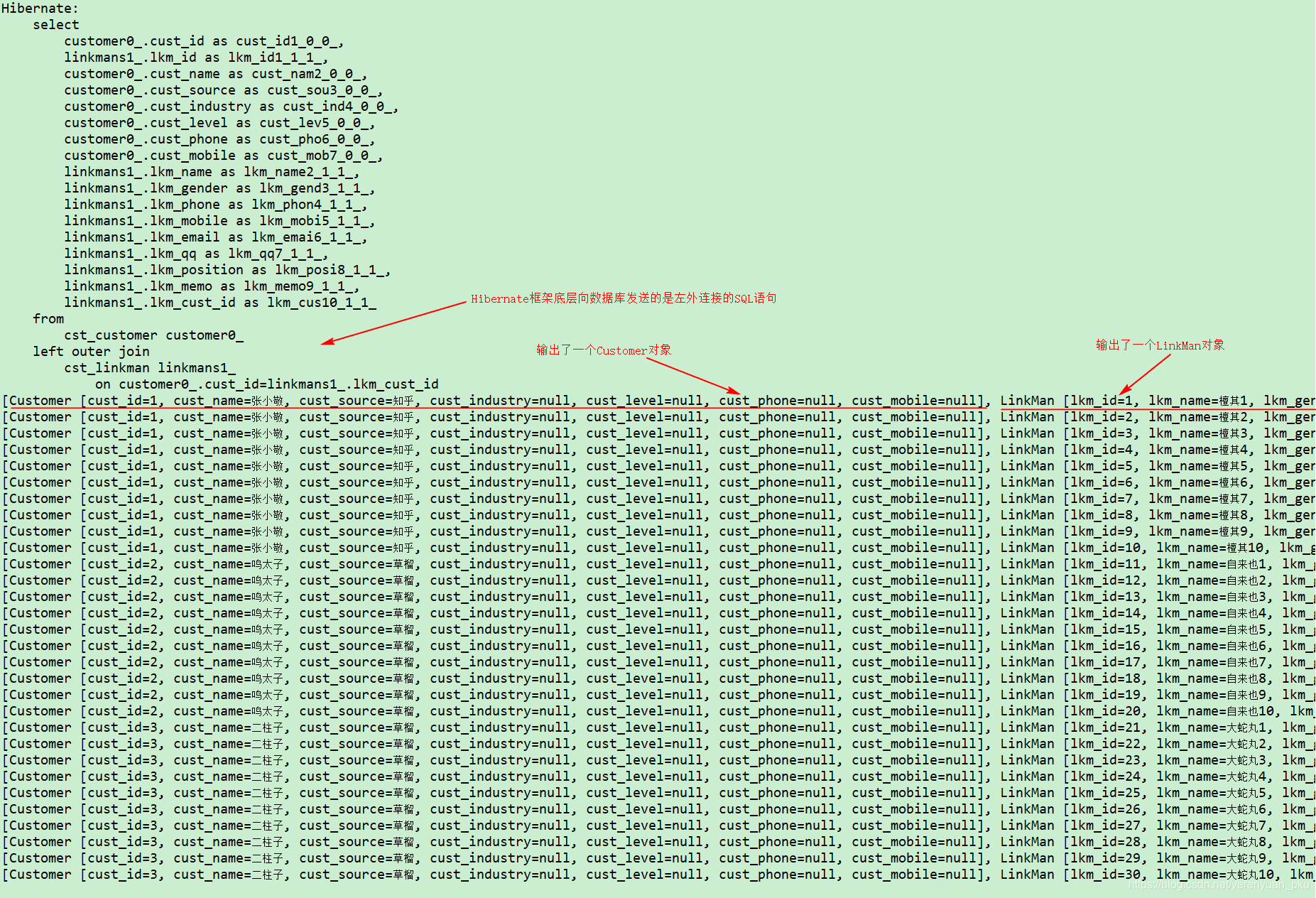
右外连接
右外连接使用的是right outer join。以码明示,在HQLJoinTest单元测试类中编写如下方法:
1 | //测试右外连接 |
注意:此时,你得重写Customer类中的toString()方法,让其不要包含linkMans属性。接着,运行以上demo04方法,Eclipse控制台将打印如下内容。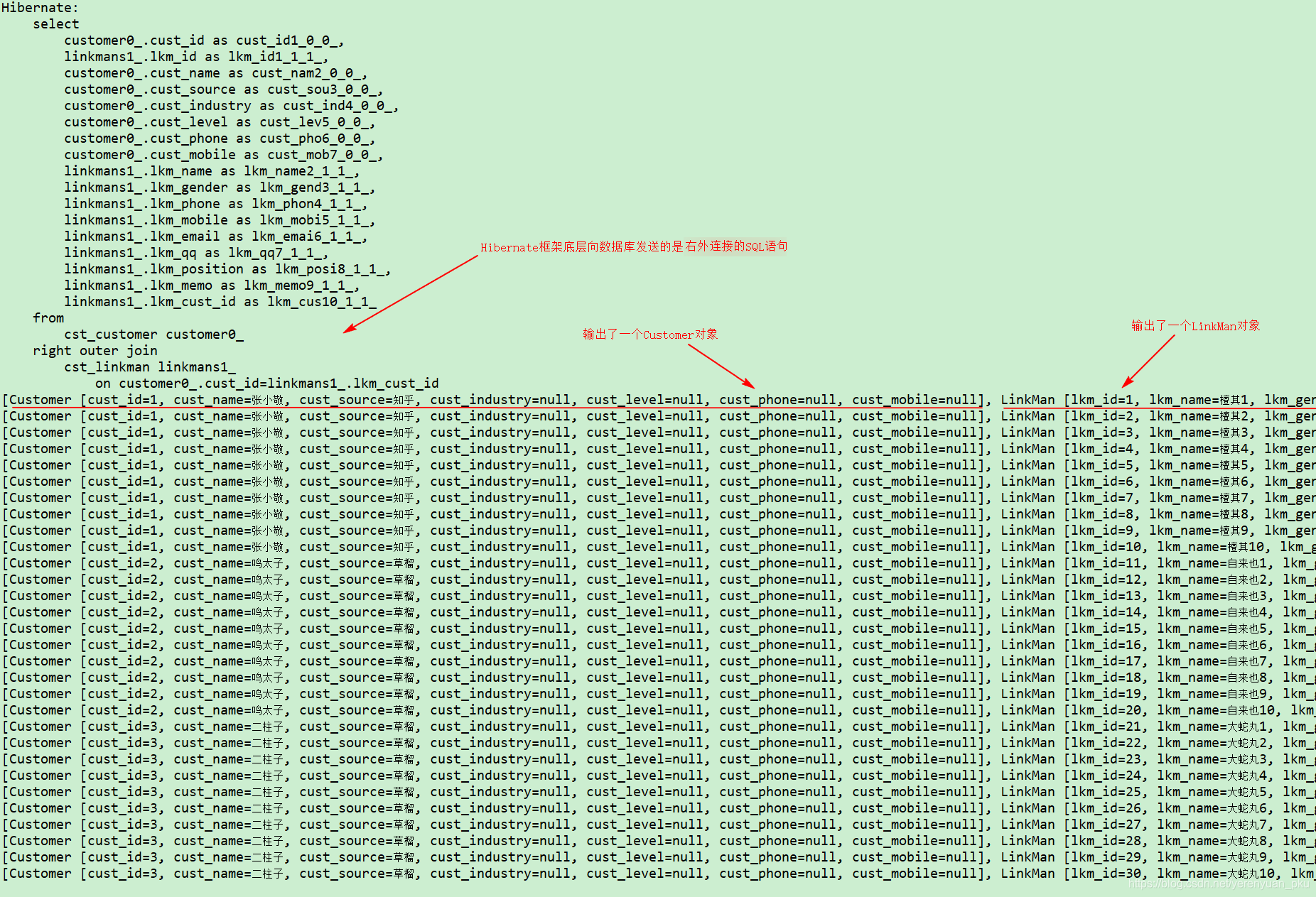
迫切左外连接
迫切左外连接使用的是left outer join fetch。以码明示,在HQLJoinTest单元测试类中编写如下方法:
1 | //测试迫切左外连接 |
与HQL迫切内连接一样,fetch关键字的作用是通知Hibernate,将另一个对象的数据封装到该对象中。在这种情境下,是指将查询出来的LinkMan对象封装到了Customer对象的linkMans集合属性中,你要是不信,可以重写Customer类中的toString()方法,如下图所示。
接着你运行以上demo05方法,哎!妈啊!咋会报如下异常呢!
异常发生的原因:fetch与单独条件的with一起使用了。如果非要让fetch与单独的一个条件使用,那么就必须使用where关键字了,所以我们可以将HQLJoinTest单元测试类中的demo05方法改为:
1 | //测试迫切左外连接 |
再次运行以上demo05方法,发现没有报错,并且Eclipse控制台会打印如下内容。
Hibernate的优化方案
一般而言,我们可以从以下两方面来优化Hibernate。
- HQL语句的优化;
- 一级缓存的优化。
HQL语句的优化
HQL语句可以从以下几个方面进行优化:
- 使用参数绑定
- 使用参数绑定的原因是让数据库一次解析SQL,对后续的重复请求可以使用生成好的执行计划,这样做节省CPU时间和内存;
- 避免SQL注入。
- 尽量少使用NOT:如果where子句中包含not关键字,那么执行时该字段的索引失效;
- 尽量使用where来替换having:having在检索出所有记录后才对结果集进行过滤,这个处理需要一定的开销,而where子句限制记录的数目,能减少这方面的开销;
- 减少对表的查询:在含有子查询的HQL中,尽量减少对表的查询,降低开销;
- 使用表的别名:当在HQL语句中连接多个表时,使用别名,提高程序阅读性,并把别名前缀与每个列连接上,这样一来,可以减少解析时间并减少列歧义引起的语法错误;
- 实体的更新与删除:在Hibernate3以后支持HQL的update与delete操作。
一级缓存的优化
一级缓存也叫做Session缓存,在一个Hibernate Session中有效,这级缓存的可干预性不强,大多于Hibernate自动管理,但它提供清除缓存的方法,这对大批量增加(更新)操作而言是有效果的,例如,同时增加十万条记录,按常规进行,很可能会出现异常,这时可能需要手动清除一级缓存,session.evict以及session.clear。
Hibernate的抓取策略(对于查询关联对象的一种优化)
延迟加载
延迟加载是Hibernate为提高程序执行的效率而提供的一种机制,即只有真正使用该对象的数据时才会创建。说人话就是:延迟加载也叫懒加载(lazy),当执行到该行代码的时候,不会发送语句去进行查询,只有在真正使用这个对象的其他属性的时候才会真正发送SQL语句进行查询。还记得load方法采用的策略是延迟加载,get方法采用的策略是立即加载吗?延迟加载可分为两类,它们分别是:
- 类级别的延迟加载;
- 关联级别的延迟加载。
下面我就简单说说它俩。
类级别的延迟加载
类级别的延迟加载指的是通过load方法查询某个对象的时候,是否采用延迟(默认采用的就是延迟加载)。例如,
1 | Customer c = session.load(Customer.class, 1l); |
类级别的延迟加载可以通过<class>元素的lazy属性来设置,默认值是true。即默认是延迟加载。如果为了显示的声明出来,那么我们可以在映射配置文件中设置如下,注意:<class>元素上的lazy属性只对普通属性有效,对关联对象无效。
如果想让类级别的延迟加载失效,那么该咋办呢?总共有三种方式可让类级别的延迟加载失效,下面我会分别介绍它们。
- 第一种方式:将
<class>元素上的lazy属性设置为false。
为了便于演示这种方式,我们在com.meimeixia.hibernate.demo02包下编写一个LoadTest单元测试类,并在该类中编写如下demo01()测试方法。
以上程序证明了如果将<class>元素上的lazy属性设置为false,代表类级别的延迟加载失效,这时load与get方法就完全一样了,都是立即加载。
虽然我们是知道了load方法采用的策略是延迟加载,get方法采用的策略是立即加载,但是什么时候用get方法,什么时候用load方法呢?如果你查询的数据非常大,例如说它里面有一些大的字段,这个时候建议你采用load方法,不要一上来就立即加载,把我们的内存占满,这样可以让我们的性能得到一部分的提升;如果你查询的数据非常少,直接get就无所谓了,因为它不会占用我们很多的内存。 - 第二种方式:将持久化类使用final修饰,例如:

- 第三种方式:调用Hibernate.initialize()方法,例如:

Hibernate这个框架是在dao层进行操作的,如果说我现在采用了一个load的方案去获取了一个对象,我们最终会把Session关闭再返回,那么我们就要把这个对象返回到service层,最后再返回到web层,这个时候load出来的代理对象其实还没有对数据进行初始化,也即它里面还没有真正有数据,返回的时候就出问题了,那如何对一个延迟的代理对象进行初始化呢?这个时候,你就要调用Hibernate.initialize()方法对load出来的代理对象初始化一把了。
关联级别的延迟加载
查询到某个对象,获得其关联的对象或属性,这种就称为关联级别的延迟加载。说得更大白话一点:关联级别的延迟加载指的是在查询到某个对象的时候,查询其关联的对象,是否采用延迟加载。例如,
1 | Customer customer = session.get(Customer.class, 1l); |
因为抓取策略往往会和关联级别的延迟加载一起使用,优化语句,所以下面就要研究抓取策略了。
抓取策略
抓取策略的概述
抓取策略指的是查找到某个对象后,通过这个对象去查询关联对象的信息时的一种策略。我们知道Hibernate中对象之间的关联关系有三种:
这里我们主要讲的是在<set>与<many-to-one>这两个标签上设置fetch、lazy属性,为何要设置这俩哥们呢?因为通过一个对象抓取到其关联对象时,需要发送SQL语句,SQL语句到底何时发送,发送成什么样的格式,这就需要通过抓取策略来进行配置了。
- fetch属性主要描述的是SQL语句的格式,例如是多条,还是子查询,还是多表联查;
- lazy属性用于控制SQL语句何时发送。
我在这里举个例子说明下,例如现在要查询一个客户,并且还要关联查询他名下的联系人。客户代表一的一方,在客户实体类中有Set集合来描述其名下的联系人,那么客户映射配置文件就应该是这样子的配置:
此时,我们就可以在set标签上设置fetch和lazy这两个属性了。
再比如,查询一个联系人时,要查询关联的客户信息。联系人代表多的一方,在联系人实体类中有Customer对象来描述其关联的客户,在联系人映射配置文件中我们使用的是<many-to-one>标签,如下图所示。
此时,我们亦可在该标签上设置fetch和lazy这两个属性。当然了,你也可在<one-to-one>标签上设置这两个属性。
知道抓取策略要干的事之后,接下来,我将会花大篇幅来讨论<set>与<many-to-one>这两个标签上的fetch属性和lazy属性到底该如何设置,以优化发送的SQL语句。
<set>标签上的fetch与lazy
<set>标签上的fetch和lazy这两属性主要是用于设置关联的集合信息的抓取策略。
- fetch属性:抓取策略,用来控制在查询关联对象时的SQL语句的格式。其可取值有:
- select:默认值,发送普通的select语句查询关联对象;
- join:发送一条迫切左外连接来查询关联对象;
- subselect:发送一条子查询去查询其关联对象。
- lazy:延迟加载,控制查询关联对象的时候是否延迟。其可取值有:
- true:默认值,查询关联对象的时候,采用延迟加载;
- false:查询关联对象的时候,不采用延迟加载;
- extra:极其懒惰,也就是说你用什么样的SQL语句,就发送什么样的SQL语句。
这样看来,fetch与lazy的组合就有九种了,其实不然,fetch与lazy的组合实际上只有七种.
第一种组合(默认情况)
在com.meimeixia.hibernate.demo02包下编写一个SetFetchTest单元测试类,并在该类中编写如下测试方法:
1 | package com.meimeixia.hibernate.demo02; |
在Customer customer = session.get(Customer.class, 1l);这句代码上加上一个断点,然后以debug的方式调试该程序,就能得出结论:会首先查询客户信息,当需要联系人信息时,才会关联查询联系人信息,并在Eclipse控制台打印如下SQL语句:
第二种组合(fetch设置为select、lazy设置为false,会直接发送两条sql语句)
首先,确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在Customer customer = session.get(Customer.class, 1l);这句代码上加上一个断点,然后以debug的方式调试该程序,就能得出结论:当查询客户信息时,也会将联系人信息查询出来,也就是说联系人信息没有进行延迟查询,可以看到Eclipse控制台打印了如下的SQL语句:
第三种组合(fetch设置为select、lazy设置为extra)
首先,确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在Customer customer = session.get(Customer.class, 1l);这句代码上加上一个断点,然后以debug的方式调试该程序,就能得出结论:当查询客户信息时,不会去查询联系人的信息,当需要该客户所关联的联系人个数时,也不会去查询联系人的信息,只会通过count来统计联系人的个数,可以这样讲,当我们使用Set集合的size()、contains()或isEmpty()等方法时,是不会去查询联系人的信息的。而且可以看到Eclipse控制台打印了SQL语句:
第四种组合(fetch设置为join、此时lazy失效)
如果fetch选择的是join方案,那么lazy它就会失效。生成的SQl语句采用的是迫切左外连(left outer join fetch),也就是说这个时候会多表联查,既然是多表联查,就会把信息都查询出来,它既然是一个迫切左外连接,那么它就会根据你的需求把信息封装到你指定的对象里面,所以lazy它就会失效。
为了测试这第四种组合,首先确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在Customer customer = session.get(Customer.class, 1l);这句代码上加上一个断点,然后以debug的方式调试该程序,你将在Eclipse控制台看到如下SQL语句:
第五种组合(fetch设置为subselect、lazy设置为true)
为了测试这第五种组合,首先确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在List<Customer> list = session.createQuery("from Customer").list();这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:会生成子查询,但是我们在查询客户所关联的联系人信息时采用的是延迟加载。你可以在Eclipse控制台看到如下SQL语句:
第六种组合(fetch设置为subselect、lazy设置为false)
为了测试这第六种组合,首先确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在List<Customer> list = session.createQuery("from Customer").list();这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:会生成子查询,在查询客户信息时,就会将客户所关联的联系人信息也查询出来。你可以在Eclipse控制台看到如下SQL语句:
第七种组合(fetch设置为subselect、lazy设置为extra)
为了测试这第七种组合,首先确保客户那方的映射配置文件是下面这样子的。
然后,在SetFetchTest单元测试类中编写如下测试方法:
1 | /* |
在List<Customer> list = session.createQuery("from Customer").list();这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:当查询客户信息时,不会去查询联系人的信息,当需要该客户所关联的联系人个数时,也不会去查询联系人的信息,只会通过count来统计联系人的个数,即会发出select count(lkm_id) from cst_linkman where lkm_cust_id =?这样的SQL语句查询出该客户所关联的联系人个数。你可以在Eclipse控制台看到如下SQL语句:
小结
在实际开发中,一般都会采用默认值。如果有特殊的需求,可能需要配置join。
<many-to-one>标签上的fetch与lazy
<set>标签上的fetch与lazy这两属性主要是设置在获取到代表一的一方时,如何去查询代表多的一方。在这一章节中,我们讨论的是在<many-to-one>(或者<one-to-one>)标签上如何设置fetch和lazy这两属性,然后去查询对方。对于我们的程序而言,就是在代表多的一方如何查询代表一的一方的信息。例如,获取到一个联系人对象,要查询其关联的客户信息。
- fetch属性:抓取策略,用来控制在查询关联对象时的SQL语句的格式。其可取值有:
- select:默认值,发送普通的select语句查询关联对象;
- join:发送一条迫切左外连接来查询关联对象。
- lazy:延迟加载,控制查询关联对象的时候是否延迟。其可取值有:
- proxy:默认值,是否采用延迟不由本方说了算,而是需要由另一方的类级别延迟策略来决定。也就是说proxy具体的取值取决于另一端的
<class>上的lazy属性的值; - false:查询关联对象,不采用延迟;
- no-proxy:由于不会使用,故在此不讨论。
- proxy:默认值,是否采用延迟不由本方说了算,而是需要由另一方的类级别延迟策略来决定。也就是说proxy具体的取值取决于另一端的
第一种组合(默认情况)
默认情况就是,在<many-to-one>标签上将fetch属性的值设置为select,lazy属性的值设置为proxy。
由于此时lazy属性的值为proxy,所以查询关联对象时,是否采用延迟不由本方说了算,而是需要由另一方的类级别延迟策略来决定。这样看来要分情况来讨论了。
第一种情况:客户映射配置文件的
<class>元素上的lazy属性设置为默认,说是默认,其实就是lazy属性值为true。
在com.meimeixia.hibernate.demo02包下编写一个OneFetchTest单元测试类,并在该类中编写如下测试方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33package com.meimeixia.hibernate.demo02;
import org.hibernate.Session;
import org.hibernate.Transaction;
import org.junit.Test;
import com.meimeixia.hibernate.domain.LinkMan;
import com.meimeixia.hibernate.utils.HibernateUtils;
/**
* <many-to-one>上的fetch和lazy的测试
* @author liayun
*
*/
public class OneFetchTest {
/*
* 默认值,即设置fetch="select"、lazy="proxy"
*/
public void demo01() {
Session session = HibernateUtils.getCurrentSession();
Transaction tx = session.beginTransaction();
LinkMan linkMan = session.get(LinkMan.class, 1l);//发送一条查询联系人的语句
System.out.println(linkMan.getLkm_name());
System.out.println(linkMan.getCustomer().getCust_name());//又会发送一条普通的select语句,去查询联系人所关联的客户
tx.commit();
}
}
1234567891011121314151617181920212223242526272829303132在
LinkMan linkMan = session.get(LinkMan.class, 1l);这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:会首先发送一条SQL只查询联系人信息,客户信息会延迟,只有真正需要客户信息时,才会发送SQL来查询客户信息。你可以在Eclipse控制台看到打印的SQL语句:
第一种情况:客户映射配置文件的
<class>元素上的lazy属性设置为false。
这时,同样以debug的方式运行demo01()方法,就能得出结论:当查询联系人时,同时也会将客户信息查询到,原因是Customer类的类级别延迟策略为false,也就是立即查询。你可以在Eclipse控制台看到打印的SQL语句:
第二种组合(fetch设置为select、lazy设置为false)
这种情况就是,在<many-to-one>标签上将fetch属性的值设置为select,lazy属性的值设置为false。
然后,在OneFetchTest单元测试类中编写如下测试方法:
1 | /* |
在LinkMan linkMan = session.get(LinkMan.class, 1l);这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:当查询联系人时,不会对客户信息进行延迟,会立即查询客户信息。你可以在Eclipse控制台看到打印的SQL语句:
温馨提示:这种组合不用理Customer类的类级别延迟策略。
第三种组合(fetch设置为join、此时lazy失效)
这种情况就是,在<many-to-one>标签上将fetch属性的值设置为join,此时lazy属性将失效,也就是说配啥都不好使。
然后,在OneFetchTest单元测试类中编写如下测试方法:
1 | /* |
在LinkMan linkMan = session.get(LinkMan.class, 1l);这句代码处打上一个断点,然后以debug的方式调试该程序,就能得出结论:如果fetch的值为join,那么lazy将失效,这时会发送一条迫切左外连接来查询,也即立即查询。你可以在Eclipse控制台看到打印的SQL语句:
这种组合当然也就不需要搭理Customer类的类级别延迟策略了。
小结
在实际开发中,一般都采用默认值。如果有特殊的需求,可能需要配置join。
批量抓取
我们在查询多个对象的关联对象时,可以采用批量抓取方式来对程序进行优化。要想实现批量抓取,可以在映射配置文件中通过batch-size属性来设置,其中batch-size属性的值表示一次抓取的条数。
获取客户的时候,同时批量去抓取联系人
首先检查两个PO类的映射配置文件是否如下:
- Customer.hbm.xml

- LinkMan.hbm.xml

为了查询出所有客户的联系人信息,我在com.meimeixia.hibernate.demo02包下编写了一个BatchFetchTest单元测试类,并在该类中编写了如下测试方法:
1 | package com.meimeixia.hibernate.demo02; |
运行以上方法,可发现Eclipse控制台打印了如下SQL语句:
从上面可以看到,首先发出了一条SQL来查询所有客户信息,然后根据客户的ID来查询联系人信息,因为有三个客户,所以发送了三条SQL,完成了查询联系人信息的操作。以上一共发送了四条SQL语句来完成操作,这就引出了一个N+1的经典问题。那咋解决这个问题呢?这时就需要采用批量抓取来解决N+1的问题了。
我们需要在客户类映射配置文件中的<set>标签上配置batch-size属性,如下:
这样再次运行demo01方法,你就可以看到Eclipse控制台打印了如下SQL语句:
获取联系人的时候,同时批量去抓取客户
为了查询出所有的联系人,然后根据联系人再查询出客户信息,我在BatchFetchTest单元测试类再编写如下测试方法:
1 | /* |
运行以上方法,可发现Eclipse控制台打印了如下SQL语句:
从上面可以看到,首先发送了一条SQL查询出所有联系人,然后再根据联系人查询出所有客户,一共4条语句完成。这时也出现了同样的N+1问题,那么当然就需要采用批量抓取来解决这个N+1问题了。注意:联系人与客户,客户它是一个主表,联系人是一个从表。在设置批量抓取时都是在主表中设置。所以,我们就要在客户类映射配置文件中的<class>标签上配置batch-size属性了,如下:
这样再次运行demo02方法,你就可以看到Eclipse控制台打印了如下SQL语句:
小结
无论是根据哪一方来查询另一方,在进行批量抓取时,都是在父方设置。如果是要查询子方信息,那么我们是在父方那个映射配置文件的<set>标签上来设置batch-size属性,如果是从子方来查询父方,也是在父方那个映射配置文件的<class>标签上设置batch-size属性。如何区分父方与子方呢?有外键的表是子方(从表),关联方就是父方(主表)。
bug
1 |
|
1 |
|